구글 Vision API를 이용한 예술작품 분석
버즈아트 http://bbuzzart.com는 신진 작가들을 위한 아트 소셜 서비스 입니다. 2015년에 서비스를 시작해서 올해로 3년차에 접어 듭니다. 사이트를 보시면 아시겠지만 다양한 작품들이 올라 옵니다. 유화, 수채화, 그래픽 아트, 사진작품까지 다양한 컨텐츠가 매일 수십 혹은 수백점씩 업로드 되고 있습니다.
2017년 상반기 버즈아트 테크팀의 기술적 목표를 컨텐츠의 개인화로 잡고 있습니다. 누가 어떤 작품을 좋아하고 작품을 좋아하는 경향이 어떤지를 분석해서 좀 더 개인화된 피드를 제공하는데 기술적 목표를 가지고 진행하려고 계획중입니다. 그런데 어떤 기준으로 이미지를 분류 해야 할지 무척 난감 하더군요.
개인적으로는 최근 머신러닝 붐도 있고 해서 이미지분석과 관련된 스터디를 작년부터 하고 있었습니다만 수학적 기반이 부족해서 상당한 고통(?)을 받고 있던 상황이라 이걸 어떻게 해결해야 하나 하는 고민을 하고 있었습니다. 그래서 미술전공한 알바를 고용해서 작품 하나하나를 다 분류 해 볼까 하는 생각까지 했었습니다만 그것도 쉬운일은 아니었습니다.
미리 말하는 결론은 구글 Vision API를 이용해서 성공적으로 약4만여작의 작품을 카테고리별로 분류 완료 했습니다. 예술 작품을 머신러닝으로 분류 한다는것 자체가 어쩌면 말도 안돼는 이야기 일 수도 있지만 어쩌면 오히려 사람이 분류 하는것보다 더 객관적인 데이터를 줄 수도 있지 않을까 하는것이 제 생각이었습니다. 그래서 머신러닝을 API로 서비스 하는 업체들을 찾기 시작 했습니다.
필요기능
처음에 서베이 해 본 머신러닝 엔진은 구글 Vision API https://cloud.google.com/vision 와 아마존 Rekognition 입니다. 구글 Vision API는 아래의 그림1과 같이 페이지에 접속해서 이미지를 드래그 드롭하는것 만으로도 테스트가 가능합니다.
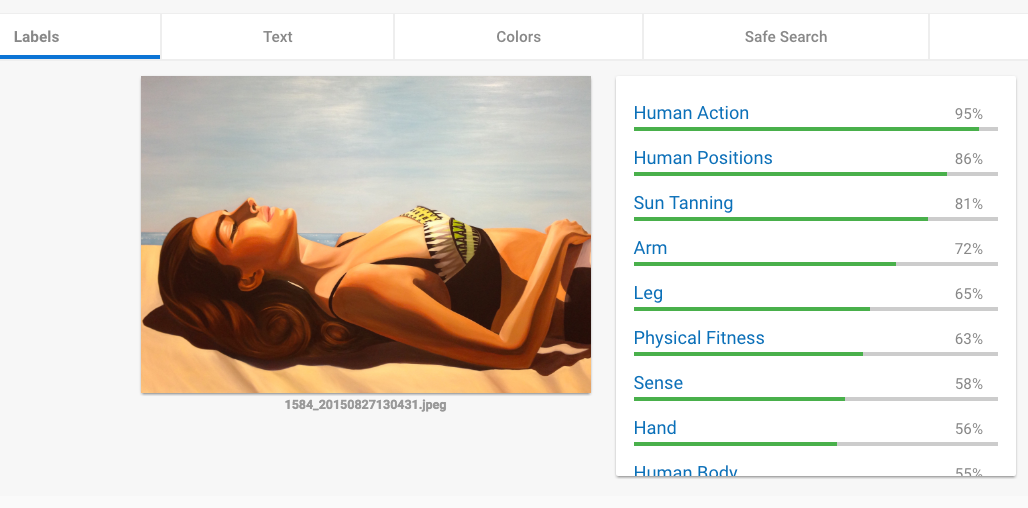
위의 그림과 같이 이미지를 드롭하면 머신러닝 분석 결과를 몇가지 타입으로 분류해 줍니다.
- Label – 이미지가 가지고 있는 내용 특성을 분류 합니다. 우측 결과처럼 그림의 애용에 따라 % 를 보여줍니다. 제가 가장 필요 했던것이 이것입니다. 예를 들면 이미지에 강아지가 있다면 Dog n%의 형태로 결과를 보여줍니다.
- Text – 이미지에 문자가 있다면 OCR 결과를 보여줍니다.
- Face – 이미지에 얼굴이 있다면 안면분석 결과도 보여줍니다.
- Color – 이미지가 가자고 있는 컬러를 정량적으로 알려줍니다.
- SafeSearch – 성인물, 폭력등의 요소가 있는지 찾아줍니다.
- 아마존 Rekonition - https://aws.amazon.com/ko/rekognition 역시 구글과 비슷한 정도의 분석 결과를 만들어 주지만 테스트 결과 안타깝게도 Color분석 기능이 없어서 제 테스트 목록에서 빠졌습니다만 대략 두 업체 모두 비슷한 정도의 가격과 성능을 보여 주고 있었습니다.

가격
각 분석엔진의 비용은 아래 링크를 참조하시면 됩니다. 결론적으로 저는 구글 API를 무료로 사용하게 되었는데 이유는 계정을 만들고 카드를 등록하니 300달러의 크레딧을 무료로 지급해 주더군요. 이미지 분석을 마치고도 꽤 많은 크래딧이 아직 남아 있습니다. ^_^
- 구글 – https://cloud.google.com/vision/pricing
- 아마존 – https://aws.amazon.com/ko/rekognition/pricing
버즈아트 작품들을 카테고리별로 분류하기 위해서는 Label, Color 두가지 요소에 대한 분석이 필요했기 때문에 구글 Vision API를 이용하기로 결정 했습니다.
개발과 API
현재 버즈아트 서버는 Java/Spring 기반으로 구성되어 있지만 간단한 유틸리티 혹은 테스트 프로젝트는 거의 Node.js기반으로 진행하고 있기 때문에 이 프로젝트 역시 Node.js로 개발하기로 하고 JavaScript API를 검색하니 아래의 링크에서 찾을 수 있었습니다.
https://github.com/googlecloudplatform/google-cloud-node#google-cloud-vision-alpha
개발을 시작하기전에 Google Console https://console.cloud.google.com을 통하여 계정에 앱과 API Key를 먼저 생성하여 준비합니다.
설치는 아래와 같이 진행합니다.
$ npm install --save @google-cloud/vision
실제 구현한 코드는 대략 아래와 같습니다.
var vision = require('@google-cloud/vision')({
projectId: 'bbuzzart-image-process',
credentials: visionkey --> 구글에서 받은 키(생략 ^^;)
});
var options = {
verbose: true,
types:[
'properties',
'label'
]
};
function detectImage(work, callback){
var img = work.thumbnailM;
var workid = work.work;
vision.detect(img, options, function (err, detections, apiResponse) {
if (err) {
if (err) console.log(err);
callback();
} else {
var colors = detections.properties.colors;
var labels = detections.labels;
async.parallel([
function(cb){
if (colors.length > 0){
addColors(workid, colors, function(err){
cb(err, workid);
});
} else {
cb('No Colors', workid);
}
},
function(cb){
if (labels.length > 0){
addLabels(workid, labels, function(err){
cb(err, workid);
});
} else {
cb('No Labels', workid);
}
}
], function(err, result){
callback();
});
}
});
}
위 코드는 실제 동작한 코드의 일부입니다. vision.detect() 함수의 결과로 JSON을 구글로부터 받아서 파싱하고 데이터베이스에 저장하는 과정을 거쳐서 아래 화면의 결과를 얻을 수 있었습니다. 물론 화면에 뿌리는 별도의 코드가 있습니다. ^^
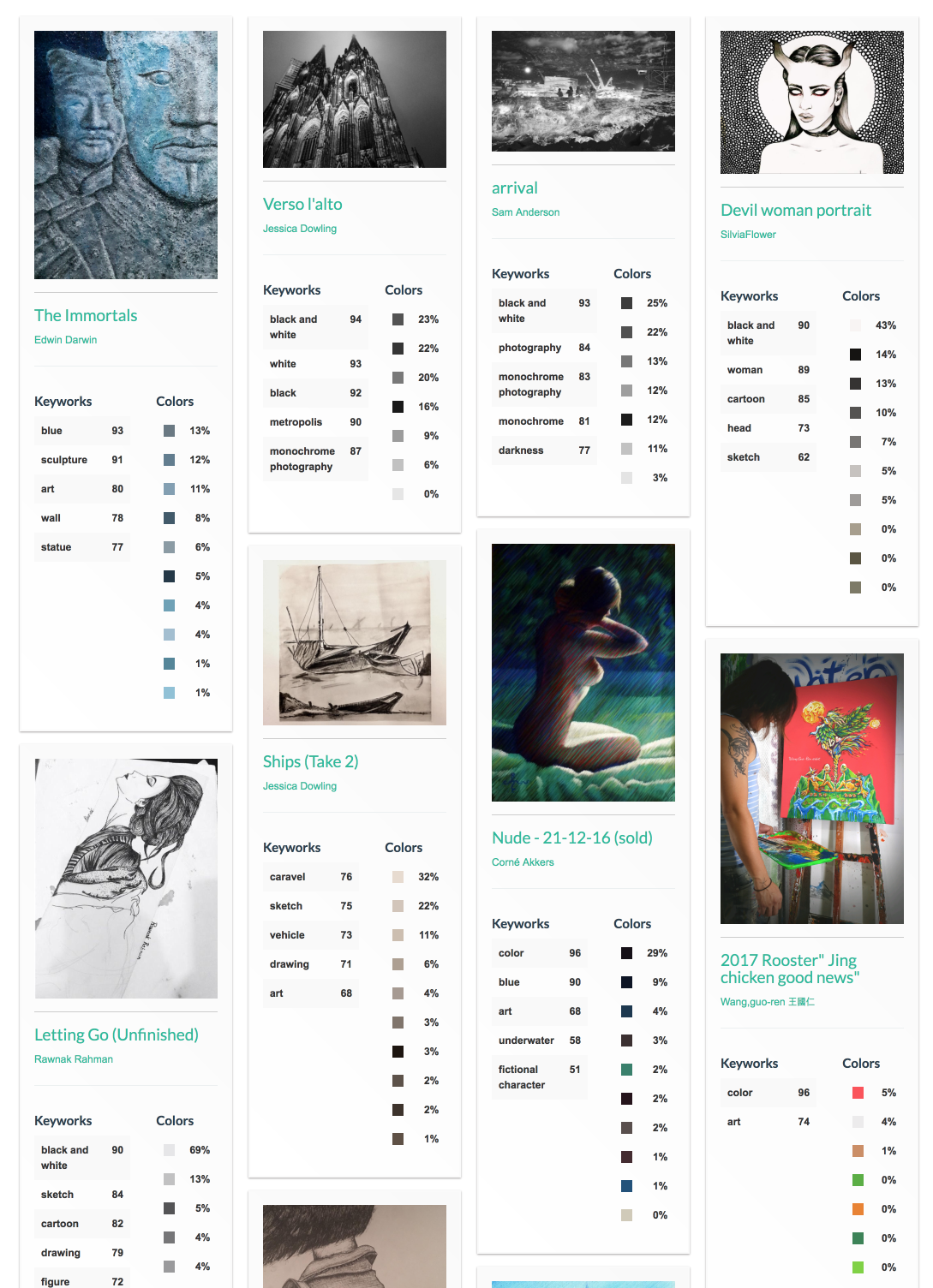
결론
작품 이미지를 분류하는 일은 피드 개인화의 가장 기초적인 작업입니다. 누가 어떤 작품을 많이 보는지 보는 사람이 좋아하는 작품이 어떤 경향을 가지는지 하는 일을 향후 더 많은 작업들을 거쳐야 하지만 이미지 컨텐츠를 서비스 하는 기업에서는 이미지에 대한 분류가 가장 기본적인 작업일것이라고 생각됩니다.
작년 알파고 사태(?) 이후로 머신러닝에 대한 관심이 개발자들 사이에서도 매우 높고 많은 책들과 자료들이 나오고 있지만 기술 난이도가 매우 높고 저와 같이 수학맹인 사람이 넘기에는 매우 높은 벽인것 같습니다. 하지만 해야하는 업무는 꼭 완수해야하는 개발자의 입장에서는 비용이 들더라도 효과적인 방법이 있다면 그걸 사용하는 것도 좋은 방법이 될것이라고 생각됩니다.
몬스터 하나를 제압 했으니 이젠 다음 스테이지로 넘어 갑니다. 또 블로깅 하겠습니다.
박병일(billy@bbuzzart.com)